Azure App Service Auto-Healing

Performance freak
Auto-healing is a mitigation action you can take when your app is having unexpected behavior. You can set your own rules based on request count, slow request, memory limit, and HTTP status code to trigger mitigation actions. Use the tool to temporarily mitigate an unexpected behavior until you find the root cause.
The “Auto-Heal” feature for Azure App Service Web apps recycles the worker process for our web application based on the settings we define, aiming to increase the reliability of our applications.
Sometimes we see performance degradation. In other cases, we experience intermittent errors that we can't easily understand. The auto-heal feature is an excellent tool for configuring custom mitigation actions to be executed when certain conditions are met (You can configure what you need).
How to Enable?
Go to your web app instance, click on “Diagnose and solve problems” and search for “Auto-Heal”
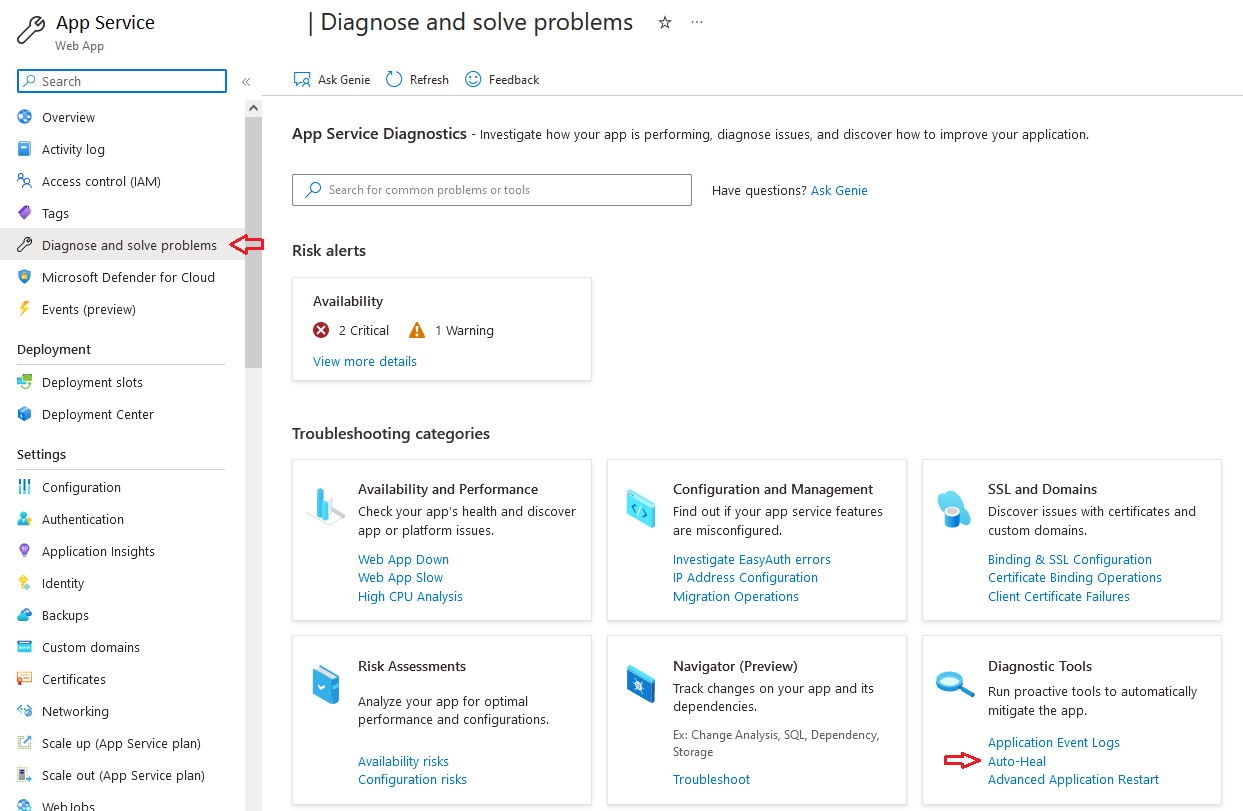
There are 2 types of Auto Healing options.
Custom Auto-Heal Rules
Proactive Auto-Heal
History: It logs all of the restart actions.
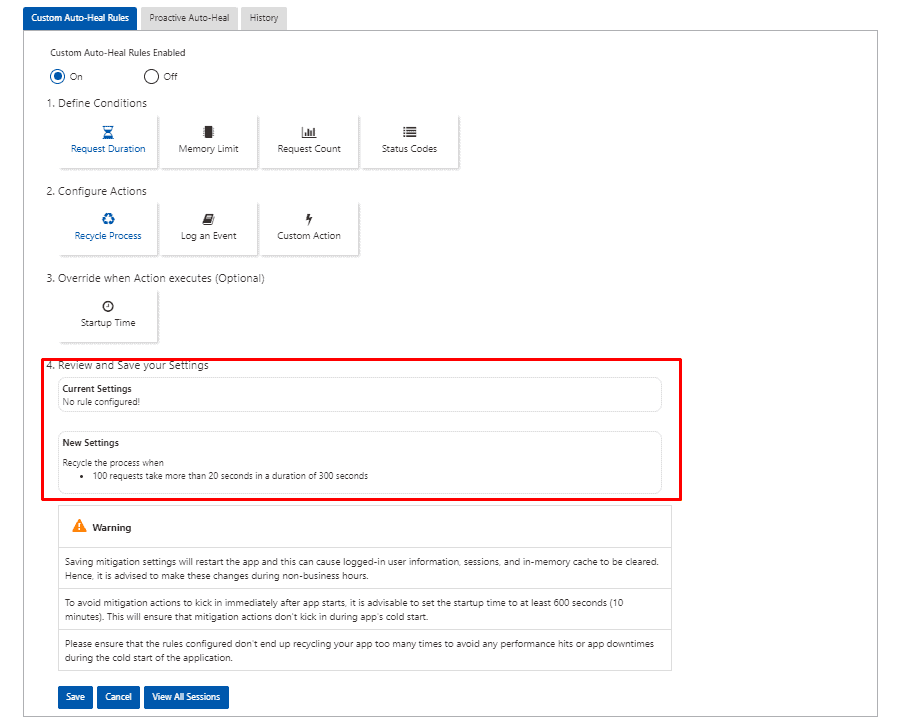
Custom Auto-Heal rules
If you want to customize how your application recycles and heals, you can do so based on different types of conditions.
Depending on the application you use, your views will likely be different. I am configuring this web application to recycle whenever there are too many slow requests. If there are 100 slow requests (taking 20 seconds or more) in the last 300 seconds, I will automatically recycle the application service.
1. Define Conditions:
The first thing we must do is select the condition we want to set on the mitigation rule.
The conditions supported on the Auto heal:
a. Request Duration: Examines slow requests.
b. Memory Limit: Examines process memory in private bytes.
c. Request Count: Examines the number of requests.
d. Status Codes: Examines the number of requests and their HTTP status code
I’m set a condition If there are 100 slow requests taking 20 seconds or more in the last 300 seconds, my app will be automatically recycled. (You can set it as per your needs)
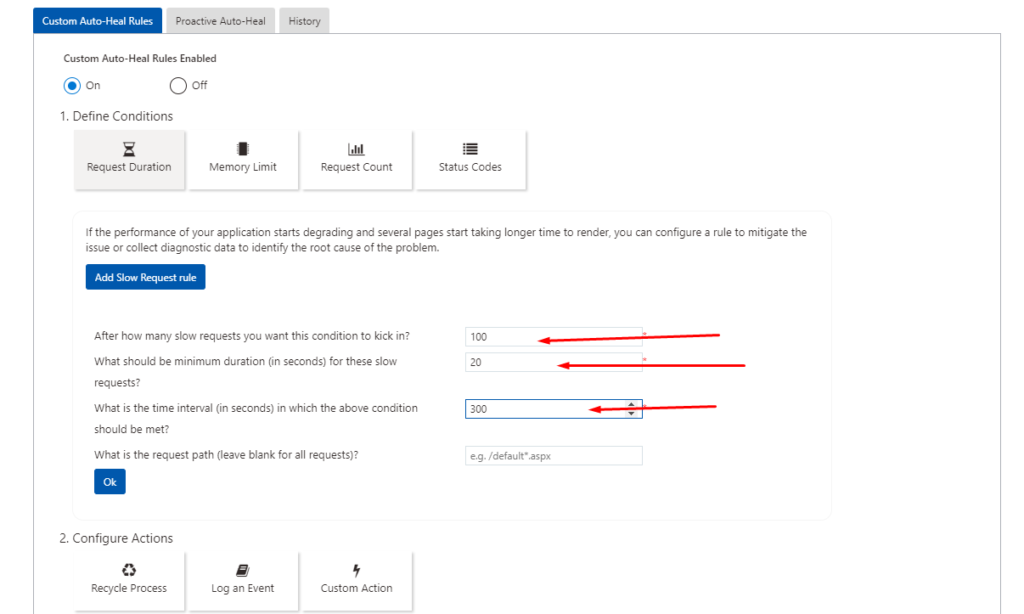
After reading the description, and adding the details, select the blue “OK” button to configure the rule parameters that you need.
2.Configure Actions:
- Select the option that best matches the auto heal mitigation action that you need to perform under the mitigation rule conditions that we configured on the above step.
The auto-heal feature supported 3 possible actions to mitigate the problems:
Recycle Process:
Log an Event:
Custom Action:
Run Diagnostics
Memory dump
Java Memory Dump
Java Thread Dump
CLR Profiler
CLR Profiler with Thread Stacks
Run Any Executable
Collect, Kill, and Analyze
In this mode, data is collected and the process is terminated when the configured condition is met. Furthermore, the data is analyzed, and an analysis report is created.
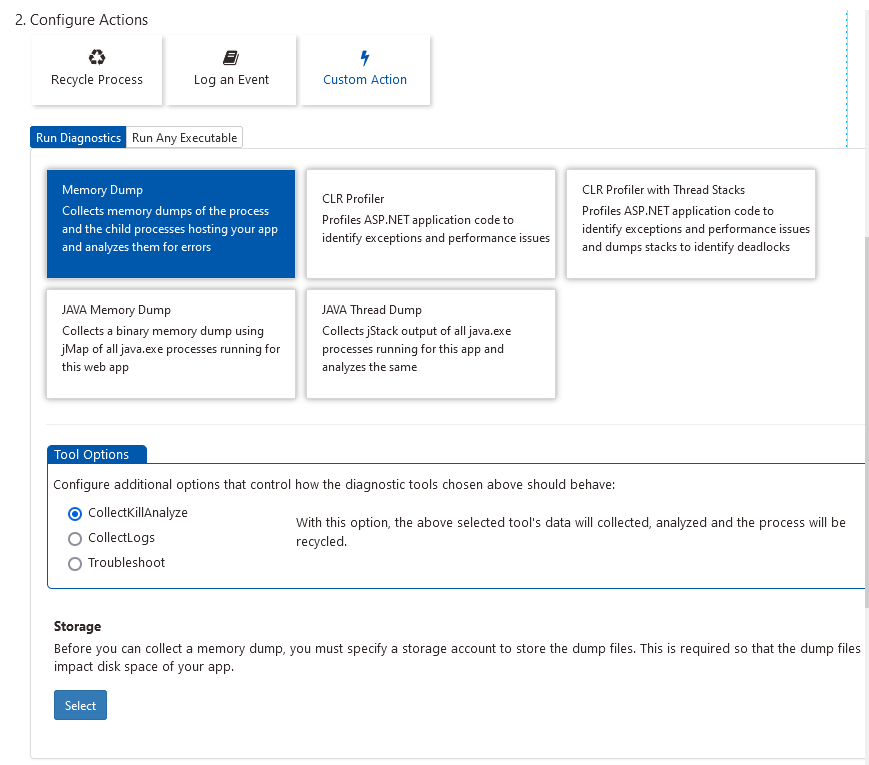
I’m selecting the “Recycle Process” action, it will automatically recycle our web app when a certain condition is met.
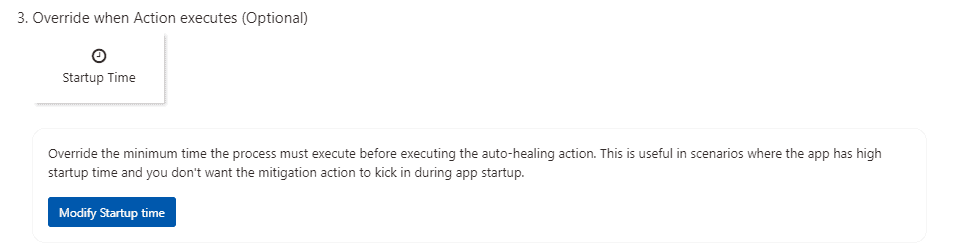
3.Override When Action Executes
When an app has a long startup time, depending on the mitigation rule conditions that are set, the mitigation action may be initiated during app startup, which is not the intended use case. By modifying the startup time, you can specify how long the mitigation rule should wait after the process starts before kicking in.
It is optional that’s why I’m not selecting it there is nothing to set for modified startup time but you can select it If you need it.
4.Review and Save your Settings
Because saving the settings causes the application to restart, we recommend making these changes outside of business hours.
We must keep in mind that these mitigation actions should only be considered a temporary workaround. The goal of this feature is to provide tools that can assist in determining the cause of unexpected behavior.
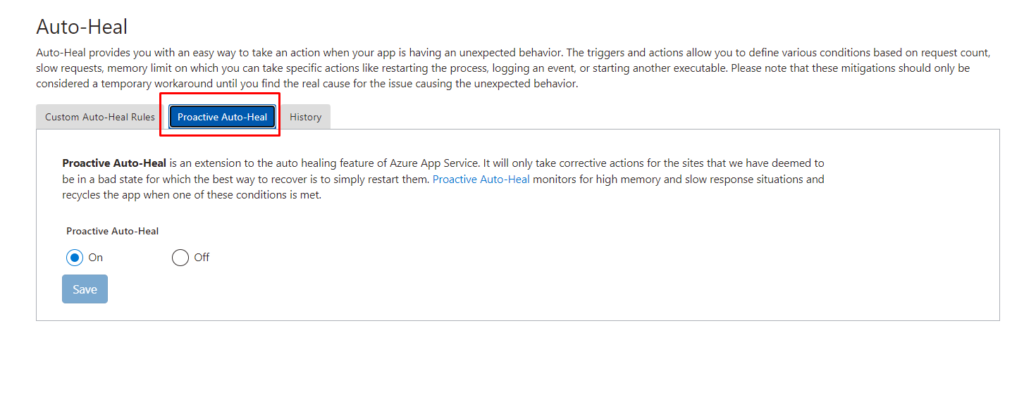
Proactive Auto-Heal
The next step is to set up a proactive auto-heal that is totally automated by the Azure service.
By default, proactive AutoHeal will be enabled for your App Service. It will watch out for high memory usage or slow requests and will restart your process for you.
Proactive Auto-Heal is an addition to Azure App Service’s auto-healing feature. It will only take corrective actions for sites that we have determined are in a bad state and can be recovered by simply restarting them. When one of these conditions is met, Proactive Auto-Heal recycles the app. It monitors for high memory and slow response situations.
How does Proactive Auto Heal know when to restart my Web App?
Curious about how this feature works behind the scenes? Proactive Auto Heal looks for Web Apps that break either of these rules:
Percent Memory Rule: This rule monitors the Web App’s process' private bytes to see if it exceeds 90% of the limit for over 30 seconds. The limit is determined by the amount of memory available for the process. For example, for a 64 bit process on a Medium worker, it would be recycled if the private bytes went above 3.5GB * 90% = 3.15 GB for over 30 seconds.
Percent Request Rule: This rule monitors requests that have taken longer than the time limit. It is broken when 80% (or more) of the total number of requests have taken 200+ seconds. The rule only triggers when there have been at least 5 requests in a rolling time window of 120 seconds during which the rule is broken. To account for slow application starts (which can be mitigated with our Application Initialization Feature with Slots!), this rule is not active during the process warm-up time.
If either of the rules is broken, then the Web App will undergo an overlapped restart of the process. This is NOT an instance restart or an entire Web App restart. In the case when there are multi-instances, the rules are ONLY triggered for the particular instance on which the process breached the rule, leaving the rest of the instances unaffected. Additionally, to prevent too many restarts (due to the application itself or service-related bugs), both rules will be auto-disabled for 3 hours if there are too many restarts detected in a small time window.
Opting Out
Because we believe that most customers can benefit from Proactive Auto Heal, we have automatically enabled it by default, so you don’t have to worry about turning this on yourself or early wake-up calls perform a manual restart of the process. However, we understand that some of you may be saying, “I don’t want you restarting my Web App!”. For example, this could be because you keep a lot of data in memory and do not want to unknowingly lose this data, which would happen when the process restarts. Here’s how you can opt-out:
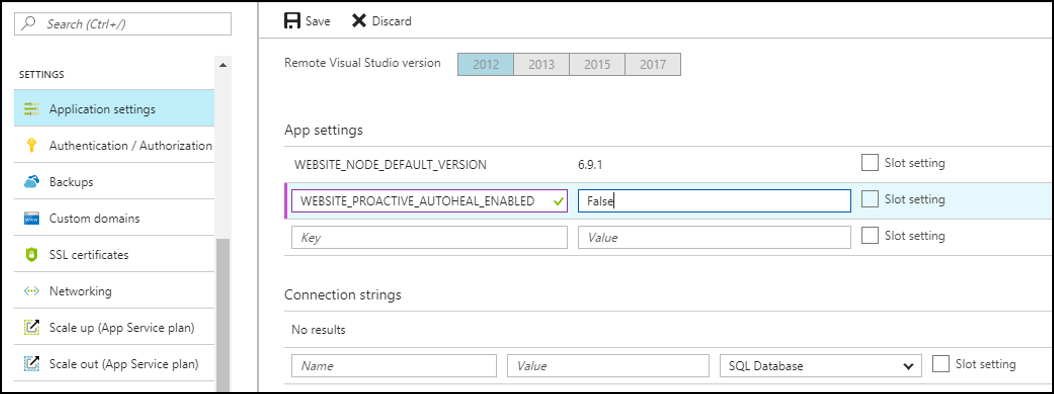
Go to portal.azure.com and go to your Web App for which you would like to disable the feature.
Under Settings go to Application Settings.
Under App Settings add “WEBSITE_PROACTIVE_AUTOHEAL_ENABLED” and set it to “False.”
That’s it! Proactive Auto Heal is disabled.
If you later decide to enable it again, you can either remove this App Setting or set it to “True”.
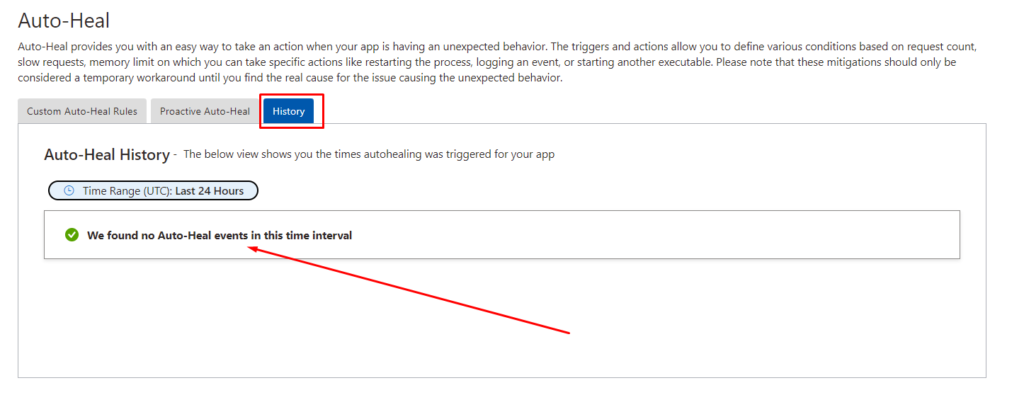
History of Auto-Heal Triggers
Fortunately, my apps have been behaving well recently, and I don’t have any historical events or recycles. However, if your app has been auto-healed and recycled, or if it has performed other actions according to your custom rules, you will see it here.
What happens to existing requests when auto-heal restarts an app?
Auto-Healing does not change the instance of the app. Whenever the configured condition criteria are met, Auto-healing recycles the worker process serving the requests on the same instance.
Whenever the process is recycled via Auto-healing, a new w3wp.exe will spun up and will start picking up new requests that are currently in the HTTP.SYS queue. The in-flight (requests that are already picked up by the old worker process) are allowed to finish gracefully and then the process is allowed to exit. The old process is given 60 (or 90 seconds, need to check) to exit and if within that time the process has not finished serving all the in-flight requests, the process will be terminated.
What is the difference between Health Check and Auto-Heal?
The Health Check feature is pretty basic compared to Auto-Heal. Basically, it makes a request to a predefined URL and if it does not get a successful response it will take that instance out of the load balancer pool. If it remains unhealthy it will be replaced with a new instance. It works only if scale-out is applied to the web app.
Auto-Heal is much more sophisticated: instead of pinging a URL it can be configured to restart an instance when a certain memory or CPU usage limit is reached, or when the response time is degraded during a certain period.
For more information:




